系统设计文档
一、项目概述
核心目标
实现从异构数据源采集到结构化决策报告的全流程自动化,融合网络爬虫、多AI协同分析与可视化技术。 实现类似comfyUI工作流,可以快速配置任务并执行。
技术亮点
- 多模态数据处理:文本、结构化数据、时序数据的统一治理
- AI增强分析:预训练模型与Prompt工程的动态结合
- 闭环交付体系:Dashboard交互式探索 → PDF标准化输出
二、技术架构
系统采用模块化设计,各组件通过标准接口相互协作:
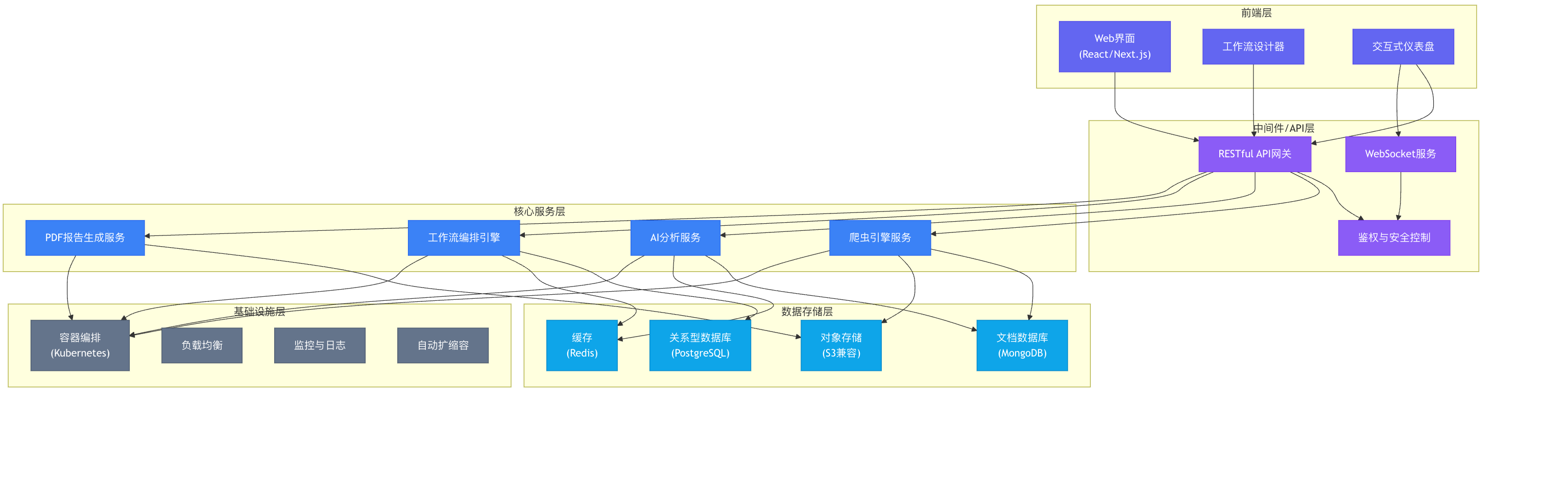
三、核心模块详解
1. 智能爬虫预处理层
- 自适应解析器:基于URL特征选择Cheerio/Puppeteer
- 动态反爬策略:IP轮换 + 浏览器指纹模拟(puppeteer-extra-plugin-stealth)
- 增量抓取:基于SimHash的内容去重算法
2. 数据清洗与增强
多级清洗流水线:
const pipeline = [
removeHTMLTags, // 去标签
extractKeyFields, // 正则匹配关键字段
normalizeText, // 标准化(如时间格式转换)
crossValidateWithAPI // 调用第三方API补全数据
];数据质量看板:统计字段缺失率、重复值分布
3. AI处理引擎
多模型协同架构:
| 模型类型 | 功能 | 案例 |
|---|---|---|
| 预训练大模型 | 语义摘要、情感分析 | GPT-4生成报告结论段落 |
| 微调领域模型 | 垂直领域实体识别(如法律条文) | BERT+CRF的法律条款分类 |
| 外部API | 补充专业能力(如地理编码) | 高德地图API解析地理位置 |
4. 可视化与输出层
- 动态Dashboard
- 技术栈:React + ECharts + D3.js
- 特性:支持拖拽式布局、下钻分析、时序预测模拟
- 智能PDF生成器
- 模板引擎:Markdown → PDF(markdown-pdf库)
- 企业级功能:自动生成目录、页眉/页脚策略、数据溯源二维码
四、创新点设计
1. AI路由决策树
- 根据数据特征自动选择AI模型(如金融数据优先调用微调风控模型)
- 实现模型间的结果交叉验证(如GPT-4与Claude-2对比分析)
2. 自进化Prompt库
- 基于用户反馈优化Prompt模板(A/B测试留存率最高的版本)
- 构建领域知识Prompt集市(如医疗、法律垂直场景)
3. 可解释性增强
- 在PDF中标注AI置信度分数与决策依据(SHAP值可视化)
- 提供"人工复核"标记接口(用户可修正AI结果并反向训练模型)
五、实施计划
| 阶段 | 里程碑 | 交付物 |
|---|---|---|
| 第1-2周 | 爬虫引擎与清洗流水线开发 | 支持10+网站的数据采集SDK |
| 第3-4周 | AI路由框架与基础Prompt库搭建 | 3类AI模型协同工作原型 |
| 第5-6周 | 动态Dashboard开发 | 可配置可视化模块库 |
| 第7-8周 | PDF智能排版引擎优化 | 通过LaTeX模板生成学术级报告 |
| 第9-10周 | 系统集成与压力测试 | 部署文档+性能优化报告 |
六、技术栈选型
| 模块 | 推荐方案 | 替代方案 |
|---|---|---|
| 爬虫框架 | Apify SDK(支持分布式爬取) | Crawlee(开源替代) |
| 数据清洗 | jsonata(JSON转换语言) | jq(命令行工具集成) |
| AI编排 | LangChain.js(支持多模型链式调用) | 自建规则引擎 |
| 定时任务 | Bull(Redis队列管理) | Agenda(MongoDB集成) |
| PDF生成 | PDFKit(底层控制) + React-PDF(组件化) | Puppeteer(HTML转PDF) |